
TiDB-存储原理简介
一、数据存储的要求
1、数据库应该怎么存储数据
数据库最根本的功能就是把数据存下来,保存数据的方法有很多
(1)直接使用数组
最简单的就是在内存中直接构建一个数据结构(比如可以使用一个数组),保存用户
发来的数据。这个方案非常简单,性能也是非常好的。但是存在很大的缺点:数据完全在
内存中,一旦停机或者服务重启,数据就永远丢失
(2)数据丢失如何解决
为了解决数据丢失的问题,可以将数据存储在非易失性的介质中,比如硬盘这时我们
可以在磁盘上创建一个文件,收到一条数据就在文件中Append一行,这样持久化存储
数据
(3)磁盘出现故障如何解决
为了防止磁盘出现坏道,我们可以做RAID,单机冗余存储
(4)单机出现故障如何解决
但是如果机器挂了呢?我们还可以将存储改为网络存储,或者是通过硬件或者软件
进行存储复制,数据安全了
2、数据存储的其他需求
跨数据中心的容灾
写入速度如何提高
数据保存下来后是否方便读取
保存的数据如何修改,如何支持并发的修改
原子性地修改多条记录
二、TiKV的设计思想
1、TiKV的数据存储模型
TiDB是Key-Value的模型,并且提供有序遍历的方法,TiKV的主要特点就是:
TiKV可以看做一个巨大的Map
这个Map中的Key-Value是按照Key的二进制顺序有序排列的
我们可以找到某一个Key的位置,然后不断的调用Next方法以递增的顺序获取比这
个Key大的Key-Value。这里的存储模型和SQL中的Table无关,TiKV是一个巨大的分
布式Map
2、TiKV数据的持久化机制
TiKV没有选择直接向磁盘上写数据,而是将数据保存在RocksDB中,具体的数据落
地由RocksDB完成。RocksDB是一个非常优秀的开源的单机存储引擎,通过使用它TiKV
已经实现了高效可靠的本地存储
但是如何保证单机失效的情况下,数据不会丢失和出错,所以我们需要将数据复制
到多台机器上,这样一台机器挂了,在其他机器上还有副本,,所以还需要一个可靠,
高效且能处理副本失效的情况
3.TiKV的一致性设计思想-优化的Raft算法
Raft的主要就是一个一致性的协议,主要的功能是Leader选举、成员变更、日志复制
TiKV利用Raft来做数据复制,每条数据变更都会落地为一条Raft日志,通过Raft的日志复制
功能,将数据安全可靠地同步到Group的多数节点中
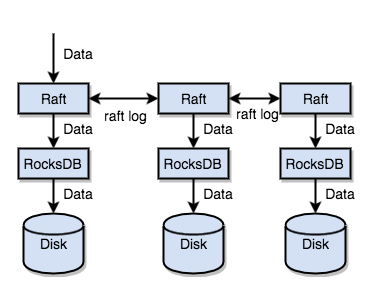
4、总结TiKV的设计思想
单机的RocksDB,将数据快速地存储到磁盘上
通过Raft协议,将数据复制到多台机器上,防止单机失效数据的写入是通过Raft这一层
的接口写入,而不是直接写入RocksDB通过Raft可以实现一个分布式的KV
三、Region
1、分布式存储的方案
对于一个KV系统,将数据分散在多台机器上一般有两种方案
一种是按照Key做hash,根据hash值选择对应的存储节点
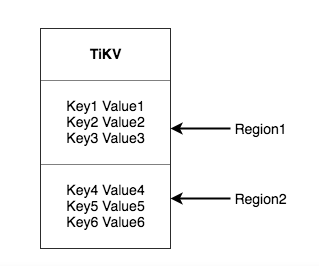
分Range,某一段连续的Key都保存在一个存储节点上,TiKV将每一个Key-Value空间
分成很多段,每一段是一系列连续的Key,我们把每一段成为一个Region每一个Region
会有最大值,目前默认64Mb,每一个Region都可以用StartKey到EndKey这样一个左
开右闭的区间来描述
2、TiDB分布式存储方案
TiDB采取了第二种方案将数据划分成Region,水平扩展和复制都是以Region为单位的
(1)数据划分成Region存储
以Region为单位,将数据分散存储在集群的所有节点上,并且尽量保证每个节点上
的服务的Region的数量差不多
数据按照Key切分成很多的Region,每个Region的数据只会保存在一个节点上面,系
统会有一个组件来负责将Region 尽可能的散布在集群中的所有的节点,一方面实现了存储
容量的水平扩展,同时也实现了负载均衡(不会出现某个节点有很多数据但是其他节点机
会没有数据的情况)
同时系统中会有一个字组件记录Region在节点上面的分布情况,即通过Key可以查
到这个Key所处的Region,以及这个Region 目前实在哪个节点上
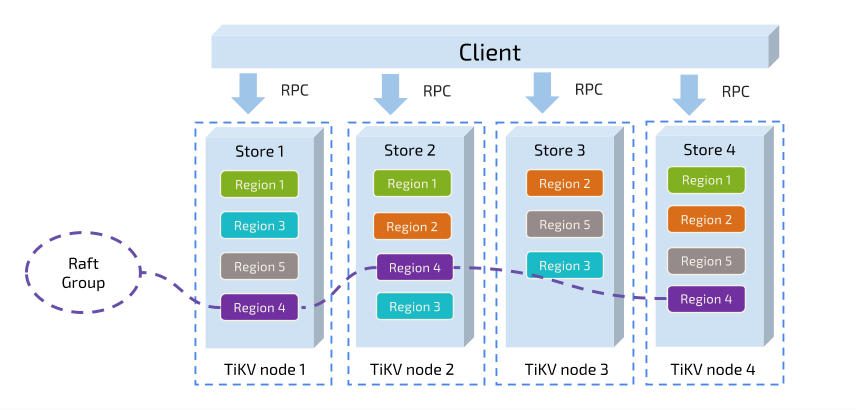
(2)以Region为单位做Raft的复制和成员的管理
每个Region的数据会保存多个副本,每个副本可称为Replica,Replica之间是通过
Raft来保持数据的一致性。一个Region的多个Replica会保存在不同的节点上,构成一
个Raft Group,其中一个Replica会作为这个Group的Leader,其他的Replica作为作为
Follower。所有的读和写都会通过Leader进行,再由Leader复制给Follower
四、并发控制
TiDB 是基于MVCC的多版本控制机制来解决并发控制的问题的
两个Client同时去修改一个Key的Value,如果没有MVCC,就需要对数据上锁,在分
布式场景下,可能会导致死锁。TiKV的MVCC实现是通过在Key后面添加Version来实现的:
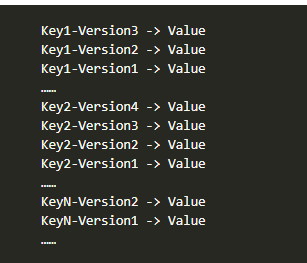
有了MVCC之后,TiKV的Key排列是这样的,对于同一个Key的多个版本,我们把
版本号较大的放在前面,版本号较小的放在后面,当用户通过一个Key+Version来获取
Value时,可以将Key和Version构造出MVCC的Key,也就是Key-Version,然后可以直接
Seek(Key-Version),定位到第一个大于等于这个Key-Version的位置即可