
TiDB-计算原理
一、关系表到KV存储的映射
1、原理
TiDB的存储引擎是一个全局有序的分布式Key-Value引擎TiDB对于每一个表分配一
个TableID,每一个索引都会分配一个IndexID,每一行分配一个RowID,TableID在整个集
群中唯一,IndexID/RowID在表内唯一,这些ID都是int64类型
2、具体实现
(1)每行数据按照如下规则进行编码
Key:tablePrefix{tableID}_recordPrefixSep{rowID}
Value:[col1,col2,col3,col4]
#tablePrefix和recordPrefixSep都是特定的字符串常量
#用于在KV空间中 区分其他的
(2)Unique Index数据的编码
Key:tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
(3)对于非Unique Index的编码
可能有多行数据的ColumnsValue一样,所以应该这样去编码:
Key:tablePrefix{tableID}_indexPrefixSep{IndexID}_indexedColumnsValue_rowID
Value:null
#Key里面的Prefix都是字符串常量,作用都是区分命名空间,
#以避免不同类型数据之间的相互冲突
每一个Table内部的所有Row都有相同的前缀,一个Index的数据也是有相同的数据的
所以可以非常方便的将Row或者Index数据有序的保存在TiKV中,即一个表中的所有Row
数据就会按照RowID的顺序排列在TiKV的Key空间中,某一个Index的数据也会按照Index
的顺序排列在Key空间内
3、元信息的管理
Database/Table都有元信息,就是表的定义和各项属性,这些信息需要持久化的存
储在TiKV中,每个Database/Table都被分配了一个唯一的ID。这个ID作为唯一的标识,
并且在编码为Key-Value,这个ID都会编码到Key中。这样可以构造出一个Key信息,
Value存储的是序列化后的元信息。除此之外,还有一个专门的Key-Value来存储当前
的Schema信息
二、TiDB的整体结构
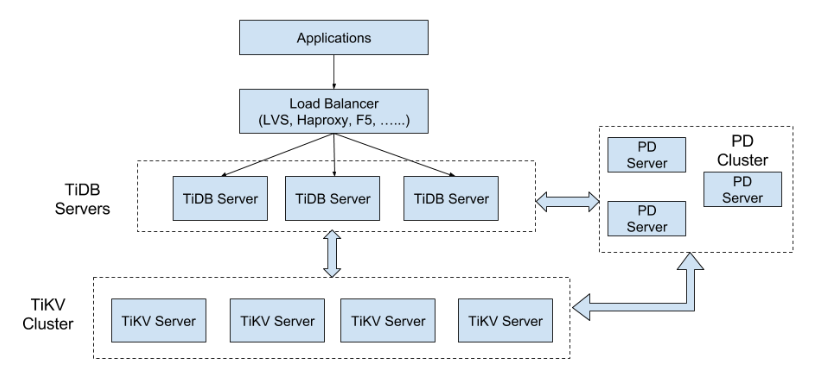
1、TiKV Cluster
主要的作用就是作为KV引擎存储数据
2、TiDB Servers
这一层就是无状态的节点,本身并不会去存储数据,节点之间完全对等;TiDB
Server这一层主要是处理用户的请求,执行SQL逻辑运算
三、SQL层运算
TiDB将SQL查询映射为KV的查询,再通过KV的接口获取对应的数据
1、查询方案的简介
以select count(*) from user where name = "TiDB"为例
- 构造Key Range:一个表中所有的RowID都在[0,MaxInt64]这个范围内,那么我们可以根
据Row Key编码规则,构造出一个[StartKey,EndKey]这样的左开右闭的区间
根据上面构造出的Key Range。读取TiKV中的数据
过滤数据,对于读取到的每一行的数据,计算name = "TiDB"这个表达式。,如果为真,
向上返回这一行,否则丢弃这一行
- 根据返回的行数计算Count值
总结该方案的缺点:
- 从TiKV中读取每一行数据时都要进行一次扫描,但是每次扫描都是一次RPC调用,当扫
描的数据很多时,这个开销非常大
不满足条件的行可以不用读取
只需统计行数即可
2、方案的改进:分布式SQL的运算
将计算、Filter、聚合函数、GroupBy尽量地靠近存储节点,以避免大量的RPC调用
数据逐层返回的示意图如下:
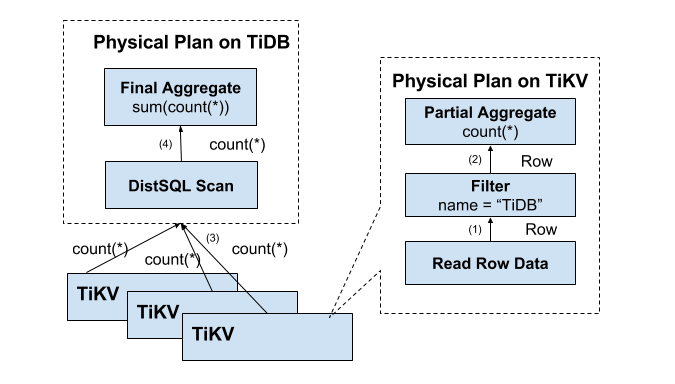
3、SQL层的架构
TiDB的SQL层是非常复杂的,这里我们简单介绍其工作原理:
用户的请求会直接或者通过Load Balancer发送到TiDB-Server,TiDB-Server会解析
MySQL Protocol Packet,获取请求的内容,然后左语法解析、查询特定和优化,执行
查询计划和处理数据。数据全部存储在TiKV的集群中,TiDB和TiKV-Server交互,获取
数据。最后TiDB-Server需要将特定的查询结果返回给特定的用户